Introduction
Recently, I worked on a project related to Smart Port, where one of the tasks was to build a service for real-time recognition of shipping container number. In simple words, this involves identifying the container numbers from images of the shipping containers. A container number is an 11-character string composed of capital letters and numbers, unique worldwide. If you’re unfamiliar with container number, you might find this article helpful.
This service processes images of containers with the output of the 11-character container number and a 4-character ISO type size code. This post will primarily focus on the container number, as the processing method for them is the same, and handling ISO code is even simpler. The image below shows several examples of container number recognition, with the container number boxed in green boxes and the ISO code in yellow box. The recognized container number is displayed in the top left corner. As you can see, container number can appear in various positions on the container, such as the door, side, top, etc.

The final system’s accuracy and stability are remarkably high, with an accuracy exceeding 99.5% (in customer test dataset). The advanced nature of the models and the extensive collection of high-quality image data are key factors for the excellent result. Due to commercial considerations of the project, the final model parameters and dataset will not be disclosed. Not every detail will be shared, but I will try to share as many ideas and techniques as possible. The images and datasets used in this post were collected from publicly available sources online during the initial phase, so they can be used with confidence. The below GIF shows the operation of container number recognition, only for demonstration and testing purposes.

This post is the first part of the series “Building a Robust Shipping Container Number Vision Recognition System”. You can find all parts here:
Part 1: Task, Challenges, Design of the System
Part 2: Tools, Image Annotation, Data Preparation
Part 3: Training, Build up the Workflow, Deployment, Takeaways
Challenges
This task might seem simple (that’s what I thought when I first heard about this project). However, it actually presents a variety of challenges and many details. Completing this project might be straightforward, but achieving excellence is challenging. Below are some notable challenges:
- Container number may be arranged horizontally or vertically. Additionally, in the photoes taken, they are not always perfectly horizontal or vertical; sometimes, there is a tilt angle. Most text recognition models perform poorly with vertically arranged text, thus requiring special handling or targeted training with a significant amount of images for vertical text.

- Most container numbers are located on the same line, but some are distributed across two or three lines. In such cases, special handling is required. We need to consider this from the data preprocessing stage and design an appropriate recognition strategy.

- Container photoes are taken in outdoor environments, so the image quality might be poor, for example, due to uneven lighting or blurriness. Some characters may be obscured by intense light or shadows. At night, with only port’s lighting, the brightness and clarity of images can significantly decrease. These factors can lead to poor model recognition performance. This is a common challenge for most computer vision tasks. Fortunately, a large high-quality dataset covering various conditions can largely mitigate this issue.

- Containers are often placed in outdoor environments, which may have their characters obscured by stains, scratches, rust, etc. These can easily lead to errors, as even humans may find it difficult to recognize them in certain scenarios. For such cases, attempts at characters correction (utilizing container number check-digit verification and practical experience) or cross-verification with existing port data, such as container arrival information, are usually required.

- The recognition system needs to be operated in real-time, thus requiring a balance between speed and accuracy. This is a typical trade-off problem between speed and accuracy. We need to maximize recognition speed while ensuring accuracy. Moreover, the system’s redundancy design must be robust to guarantee stability, especially with disaster recovery capability, since port operations are continuous for 24 hours a day. This recognition system is deployed locally in the form of Docker, offering API service. This part is not the focus of the post, as it diverges into a completely different topic.
Design of the Recognition Process
The following flowchart roughly illustrates the simplified workflow of the recognition system. CN refers to Container Number, and TS refers to ISO Type Size code (e.g., 45G1, 22G1, etc.). The figure only shows the recognition process of the container number, and the recognition process of the ISO Type Size code is similar.
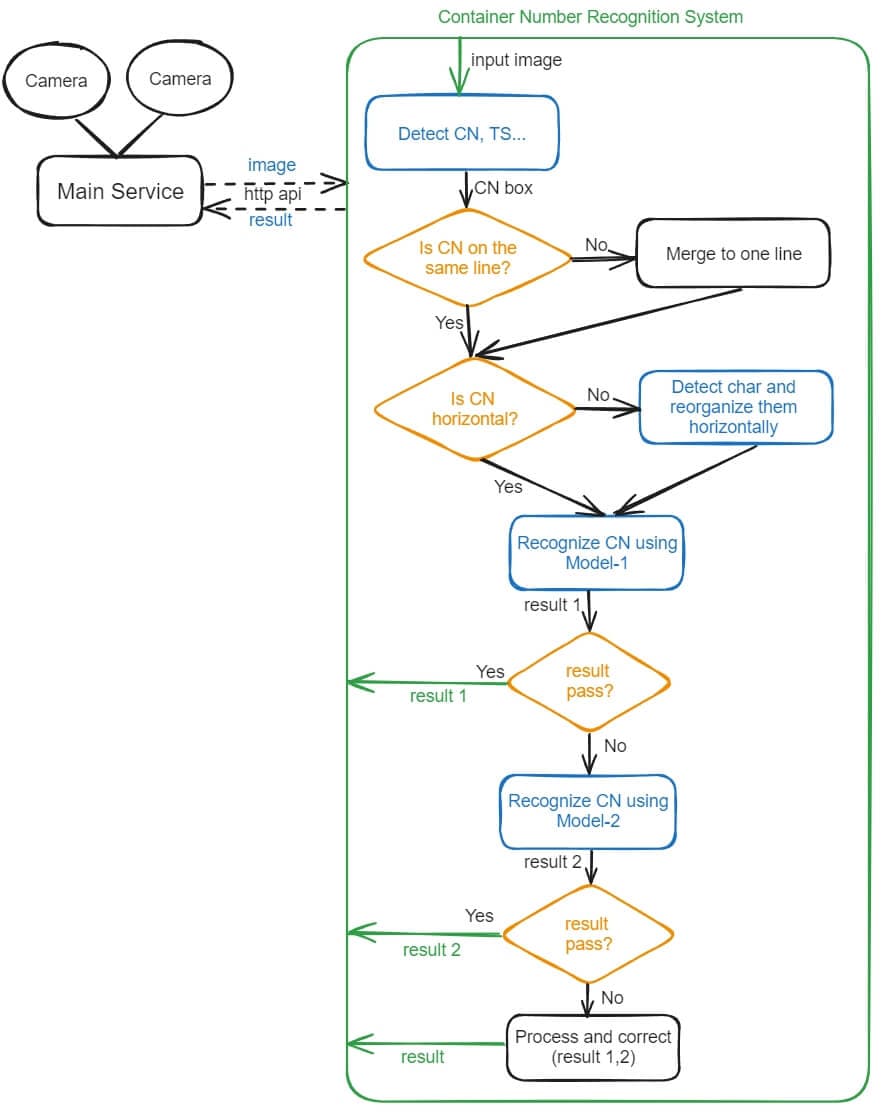
Here are some key points of the recognition process:
-
Image Preprocessing: Based on traditional image processing experience, performing some preprocessing steps, such as denoising and enhancing contrast, can improve the system’s overall performance. However, in this project, according to actual test results, these preprocessing operations are not necessary and do not improve the system’s final performance. Detection and recognition models trained with a large amount of high-quality data have strong robustness and can handle a certain degree of noise and uneven lighting. Indeed, this is one of the advantages of machine learning models, same phenomena is also observed in other image processing tasks that utilize machine learning models. The only preprocessing operation that might be necessary is image scaling. The system does not require input images in their original large sizes to achieve good recognition results, so images can be scaled down to an appropriate size to reduce computational load.
-
Container Number Detection: This is the first step in the recognition process. This detection model is responsible for locating the container number (and ISO type size code…) in the image. The model is trained using the YOLOv8 detection algorithm. It outputs the coordinates of the container number in the image, and the coordinates are used to crop the container number regions from the original image.
-
Reorganize Container Number Region:
- Merge to One Line: Because some container numbers may be distributed across two lines, it’s necessary to merge these multi-line number regions into a single line or column. This simplification facilitates subsequent recognition processing and can increase accuracy. For correct regions merging, it’s crucial to precisely detect whether a line belongs to the container number parts. Whether it pertains to the container number parts is a problem that the first-step detection model needs to address. The specific details will be introduced in later post.

- Rearrange Horizontally: If the container number is vertically arranged, it needs to be rearranged horizontally, because I want to let the system recognize horizontal texts only, most OCR models perform poorly with vertically arranged text. Here, rearranging horizontally isn’t as simple as rotating the image by 90 or 270 degrees, because such rotation would leave the characters in the image not upright. Although OCR models can recognize rotated text, considering the recognition performance and the convenience of subsequent processing, horizontally arranged text with upright characters is the best choice. The below figure illustrates the rearrangement. In this process, a new character detection model is trained to detect individual characters (using YOLOv8 detection as well), and then the system rearranges the detected characters in horizontal order.
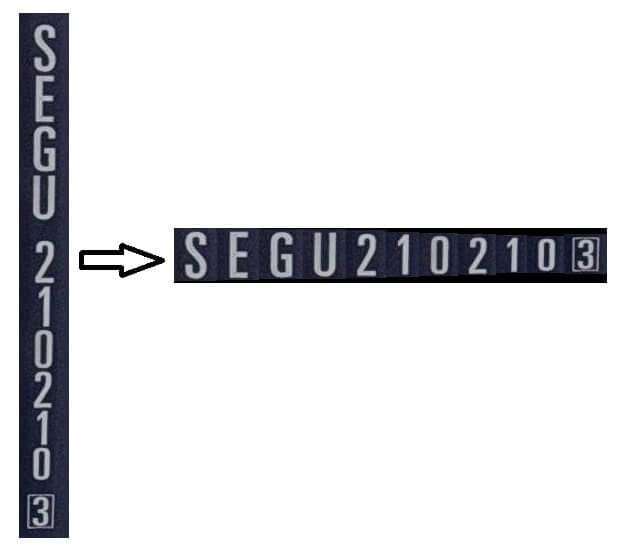
-
Container Number Recognition: Once the cropped image of horizontal container number is ready, it can be recognized using text recognition model. Here, PaddleOCR is used to train the text recognition model, which includes many popular text recognition algorithms; the details will be explained later. It’s worth mentioning that our system employs two different recognition algorithm models to recognize the container number. If the result from the first recognition model does not successfully pass the verification, the system then employs the second recognition model to do the job again. If the second model also fails, the system will compare and correct the two results to output the final result. In real-world applications, using multiple models to improve accuracy is a common practice. Of course, this inevitably increases processing time, but fortunately, this increase is acceptable within the overall system.
Note: Within the recognition system, the correctness of the recognition results can be verified using the check-digit calculation of the container number. The last character of the container number is a check-digit number, calculated based on the preceding ten characters. For the calculation rules of the check-digit, you can refer to this article.
Here is the Python function of check-digit calculation:
# Calculate the check-digit of the container number # input: container_code, first 10 characters of the container number # output: check-digit, the 11th chracter def calculate_check_digit(container_code): # Mapping letters to their corresponding values letter_values = { 'A': 10, 'B': 12, 'C': 13, 'D': 14, 'E': 15, 'F': 16, 'G': 17, 'H': 18, 'I': 19, 'J': 20, 'K': 21, 'L': 23, 'M': 24, 'N': 25, 'O': 26, 'P': 27, 'Q': 28, 'R': 29, 'S': 30, 'T': 31, 'U': 32, 'V': 34, 'W': 35, 'X': 36, 'Y': 37, 'Z': 38 } # Convert the container code into its corresponding values values = [] for char in container_code: if char.isalpha(): values.append(letter_values[char]) else: values.append(int(char)) # Calculate the sum of the values multiplied by 2^(position-1) total = sum(val * (2 ** i) for i, val in enumerate(values)) # Calculate the check digit as the remainder of division by 11 check_digit = total % 11 # If the remainder is 10, the check digit is 0 if check_digit == 10: check_digit = 0 return check_digit
Next
In the next post, I will introduce the tools, image annotation, as well as data preparation. Click here to go to the next post.